1 | import numpy as np |
1 | [[0.66992313 0.38898046 0.85090475 0.75138018] |
1 | import numpy as np |
1 | [[0.66992313 0.38898046 0.85090475 0.75138018] |
1 | import pandas |
1 | 姓名 object |
1 | import pandas |
1 | 门店 区域 11月总销售 11月总毛利 目标销售 实际完成 \ |
1 | import pandas as pd |
1 | 177 |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
| 10 | 11 | 1 | 3 | Sandstrom, Miss. Marguerite Rut | female | 4.0 | 1 | 1 | PP 9549 | 16.7000 | G6 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| 12 | 13 | 0 | 3 | Saundercock, Mr. William Henry | male | 20.0 | 0 | 0 | A/5. 2151 | 8.0500 | NaN | S |
| 13 | 14 | 0 | 3 | Andersson, Mr. Anders Johan | male | 39.0 | 1 | 5 | 347082 | 31.2750 | NaN | S |
| 14 | 15 | 0 | 3 | Vestrom, Miss. Hulda Amanda Adolfina | female | 14.0 | 0 | 0 | 350406 | 7.8542 | NaN | S |
| 15 | 16 | 1 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female | 55.0 | 0 | 0 | 248706 | 16.0000 | NaN | S |
| 16 | 17 | 0 | 3 | Rice, Master. Eugene | male | 2.0 | 4 | 1 | 382652 | 29.1250 | NaN | Q |
| 18 | 19 | 0 | 3 | Vander Planke, Mrs. Julius (Emelia Maria Vande… | female | 31.0 | 1 | 0 | 345763 | 18.0000 | NaN | S |
| 20 | 21 | 0 | 2 | Fynney, Mr. Joseph J | male | 35.0 | 0 | 0 | 239865 | 26.0000 | NaN | S |
| 21 | 22 | 1 | 2 | Beesley, Mr. Lawrence | male | 34.0 | 0 | 0 | 248698 | 13.0000 | D56 | S |
| 22 | 23 | 1 | 3 | McGowan, Miss. Anna “Annie” | female | 15.0 | 0 | 0 | 330923 | 8.0292 | NaN | Q |
| 23 | 24 | 1 | 1 | Sloper, Mr. William Thompson | male | 28.0 | 0 | 0 | 113788 | 35.5000 | A6 | S |
| 24 | 25 | 0 | 3 | Palsson, Miss. Torborg Danira | female | 8.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 25 | 26 | 1 | 3 | Asplund, Mrs. Carl Oscar (Selma Augusta Emilia… | female | 38.0 | 1 | 5 | 347077 | 31.3875 | NaN | S |
| 27 | 28 | 0 | 1 | Fortune, Mr. Charles Alexander | male | 19.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S |
| 30 | 31 | 0 | 1 | Uruchurtu, Don. Manuel E | male | 40.0 | 0 | 0 | PC 17601 | 27.7208 | NaN | C |
| 33 | 34 | 0 | 2 | Wheadon, Mr. Edward H | male | 66.0 | 0 | 0 | C.A. 24579 | 10.5000 | NaN | S |
| 34 | 35 | 0 | 1 | Meyer, Mr. Edgar Joseph | male | 28.0 | 1 | 0 | PC 17604 | 82.1708 | NaN | C |
| 35 | 36 | 0 | 1 | Holverson, Mr. Alexander Oskar | male | 42.0 | 1 | 0 | 113789 | 52.0000 | NaN | S |
| 37 | 38 | 0 | 3 | Cann, Mr. Ernest Charles | male | 21.0 | 0 | 0 | A./5. 2152 | 8.0500 | NaN | S |
| 38 | 39 | 0 | 3 | Vander Planke, Miss. Augusta Maria | female | 18.0 | 2 | 0 | 345764 | 18.0000 | NaN | S |
| … | … | … | … | … | … | … | … | … | … | … | … | … |
| 856 | 857 | 1 | 1 | Wick, Mrs. George Dennick (Mary Hitchcock) | female | 45.0 | 1 | 1 | 36928 | 164.8667 | NaN | S |
| 857 | 858 | 1 | 1 | Daly, Mr. Peter Denis | male | 51.0 | 0 | 0 | 113055 | 26.5500 | E17 | S |
| 858 | 859 | 1 | 3 | Baclini, Mrs. Solomon (Latifa Qurban) | female | 24.0 | 0 | 3 | 2666 | 19.2583 | NaN | C |
| 860 | 861 | 0 | 3 | Hansen, Mr. Claus Peter | male | 41.0 | 2 | 0 | 350026 | 14.1083 | NaN | S |
| 861 | 862 | 0 | 2 | Giles, Mr. Frederick Edward | male | 21.0 | 1 | 0 | 28134 | 11.5000 | NaN | S |
| 862 | 863 | 1 | 1 | Swift, Mrs. Frederick Joel (Margaret Welles Ba… | female | 48.0 | 0 | 0 | 17466 | 25.9292 | D17 | S |
| 864 | 865 | 0 | 2 | Gill, Mr. John William | male | 24.0 | 0 | 0 | 233866 | 13.0000 | NaN | S |
| 865 | 866 | 1 | 2 | Bystrom, Mrs. (Karolina) | female | 42.0 | 0 | 0 | 236852 | 13.0000 | NaN | S |
| 866 | 867 | 1 | 2 | Duran y More, Miss. Asuncion | female | 27.0 | 1 | 0 | SC/PARIS 2149 | 13.8583 | NaN | C |
| 867 | 868 | 0 | 1 | Roebling, Mr. Washington Augustus II | male | 31.0 | 0 | 0 | PC 17590 | 50.4958 | A24 | S |
| 869 | 870 | 1 | 3 | Johnson, Master. Harold Theodor | male | 4.0 | 1 | 1 | 347742 | 11.1333 | NaN | S |
| 870 | 871 | 0 | 3 | Balkic, Mr. Cerin | male | 26.0 | 0 | 0 | 349248 | 7.8958 | NaN | S |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard (Sallie Monypeny) | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 872 | 873 | 0 | 1 | Carlsson, Mr. Frans Olof | male | 33.0 | 0 | 0 | 695 | 5.0000 | B51 B53 B55 | S |
| 873 | 874 | 0 | 3 | Vander Cruyssen, Mr. Victor | male | 47.0 | 0 | 0 | 345765 | 9.0000 | NaN | S |
| 874 | 875 | 1 | 2 | Abelson, Mrs. Samuel (Hannah Wizosky) | female | 28.0 | 1 | 0 | P/PP 3381 | 24.0000 | NaN | C |
| 875 | 876 | 1 | 3 | Najib, Miss. Adele Kiamie “Jane” | female | 15.0 | 0 | 0 | 2667 | 7.2250 | NaN | C |
| 876 | 877 | 0 | 3 | Gustafsson, Mr. Alfred Ossian | male | 20.0 | 0 | 0 | 7534 | 9.8458 | NaN | S |
| 877 | 878 | 0 | 3 | Petroff, Mr. Nedelio | male | 19.0 | 0 | 0 | 349212 | 7.8958 | NaN | S |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
| 881 | 882 | 0 | 3 | Markun, Mr. Johann | male | 33.0 | 0 | 0 | 349257 | 7.8958 | NaN | S |
| 882 | 883 | 0 | 3 | Dahlberg, Miss. Gerda Ulrika | female | 22.0 | 0 | 0 | 7552 | 10.5167 | NaN | S |
| 883 | 884 | 0 | 2 | Banfield, Mr. Frederick James | male | 28.0 | 0 | 0 | C.A./SOTON 34068 | 10.5000 | NaN | S |
| 884 | 885 | 0 | 3 | Sutehall, Mr. Henry Jr | male | 25.0 | 0 | 0 | SOTON/OQ 392076 | 7.0500 | NaN | S |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
714 rows × 12 columns
1 | #通过行和列定位 |
1 | import pandas as pd |
1 | 365 2017-12-03 |
1 | import pandas as pd |
1 | import numpy as np |

1 | import pandas as pd |
1 | 0 135000.0 |
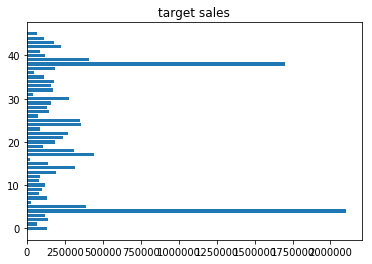
1 | #横着的树状图 |
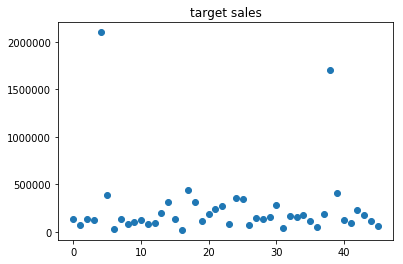
1 | #散点图 |
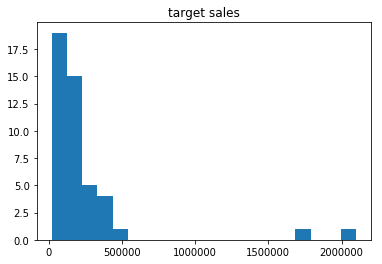
1 | import matplotlib.pyplot as plt |
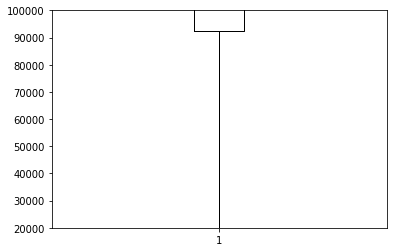
1 | fig,ax = plt.subplots() |
1 | import seaborn as sns |
1 | def sinplot(flip=1): |
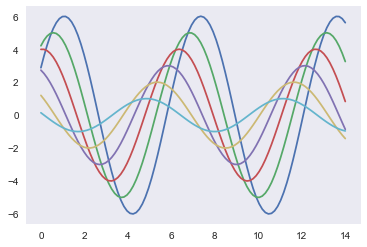
1 | sns.set() |
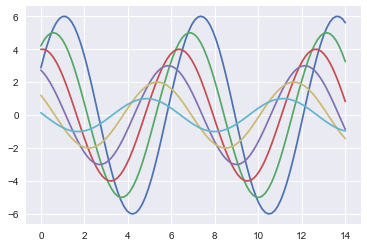
1 | sns.set_style("ticks") |
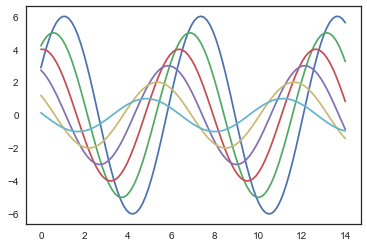
1 | sns.set_style("white") |
1 | sinplot() |
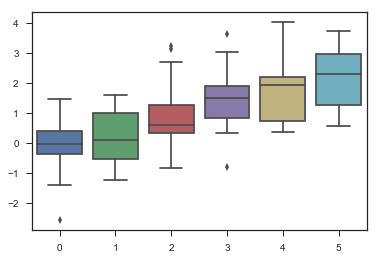
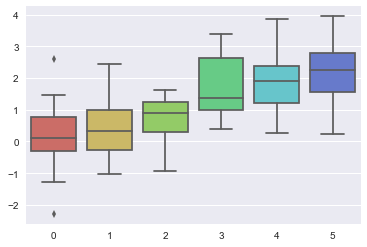
1 | sns.violinplot(data) |
1 | with sns.axes_style("darkgrid"): |
1 | sns.set() |
1 | sns.set_context("talk") |
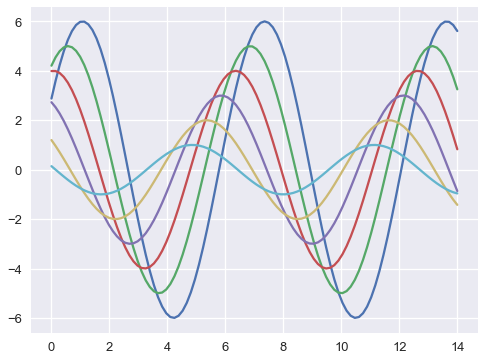
1 | sns.set_context("poster") |
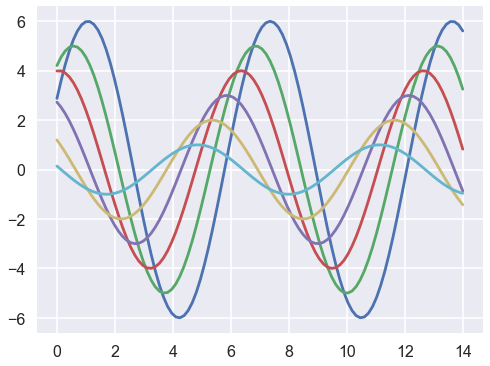
1 | sns.set_context("notebook",font_scale=2.5,rc={'lines.linewidth':4.5}) |
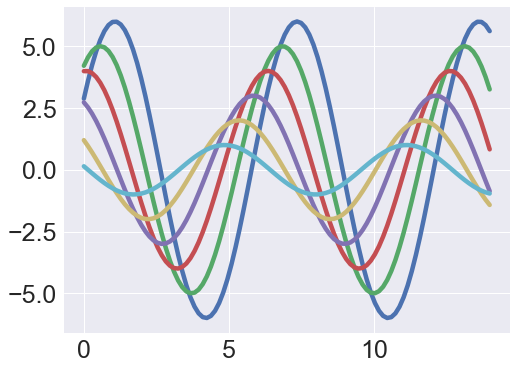
1 | import pandas as pd |
1 | current_palette = sns.color_palette() |

1 | sns.palplot(sns.color_palette("hls",8)) |

1 | data = np.random.normal(size=(20,6))+np.arange(6)/2 |
1 | #sns.palplot(sns.hls_palette(8,l=5,s=9)) |
sns.palplot(sns.color_palette(“Paired”,20))
1 | sns.palplot(sns.color_palette("Blues")) |

1 | sns.palplot(sns.color_palette("BuGn_r")) |

1 | #线性调色板 |

1 | sns.palplot(sns.light_palette("green")) |

1 | sns.palplot(sns.dark_palette("green")) |

1 | #由深到浅 |

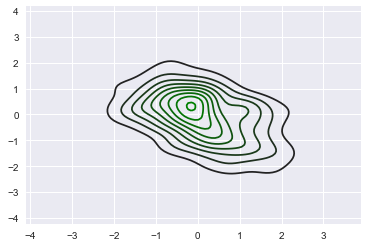
1 | x,y=np.random.multivariate_normal([0,0],[[1,-0.5],[-0.5,1]],size=300).T |
1 | import numpy as np |
1 | sns.set(color_codes = True) |
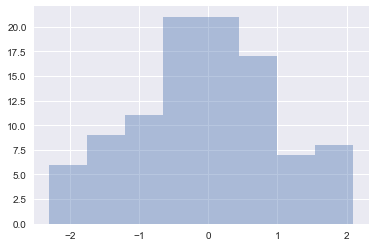
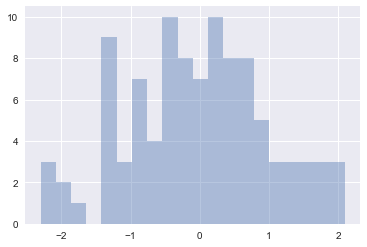
1 | sns.distplot(x,bins=20,kde=False) |
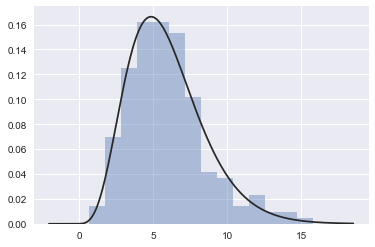
1 | x = np.random.gamma(6,size=200) |
1 | mean,cov = [0,1],[(1,.5),(.5,1)] |
| x | y | |
|---|---|---|
| 0 | -0.174087 | 1.795256 |
| 1 | -0.416757 | 0.638361 |
| 2 | -1.188138 | -0.331589 |
| 3 | -0.609992 | 0.435072 |
| 4 | -1.839588 | 1.710629 |
| 5 | -0.636881 | 0.890326 |
| 6 | -0.833977 | 0.792370 |
| 7 | 1.789158 | 2.060371 |
| 8 | 1.156777 | 0.663219 |
| 9 | 0.423476 | 0.673290 |
| 10 | -0.412169 | 0.751990 |
| 11 | -1.126475 | 0.535133 |
| 12 | 1.323243 | 1.533676 |
| 13 | -0.023044 | -0.599542 |
| 14 | 0.691180 | 0.879479 |
| 15 | 1.478605 | 2.477569 |
| 16 | -1.637043 | -0.499630 |
| 17 | -0.094884 | 2.142044 |
| 18 | -0.989239 | 1.218270 |
| 19 | 1.420987 | 1.013807 |
| 20 | 0.360396 | 2.465208 |
| 21 | 1.358501 | 1.184887 |
| 22 | 2.339145 | 1.285469 |
| 23 | 1.282484 | 2.062299 |
| 24 | 0.854708 | 0.706735 |
| 25 | -0.223393 | -0.172632 |
| 26 | -0.513652 | 0.535946 |
| 27 | 1.207449 | 1.181039 |
| 28 | -1.219564 | -1.178302 |
| 29 | -0.855500 | 0.167194 |
| … | … | … |
| 170 | 1.022425 | 1.816807 |
| 171 | 0.344980 | 0.766577 |
| 172 | 1.043292 | 0.955718 |
| 173 | 0.765037 | 2.321773 |
| 174 | 0.683540 | 0.501221 |
| 175 | 1.188854 | 0.022803 |
| 176 | -0.287907 | -0.166137 |
| 177 | -0.778977 | 0.036364 |
| 178 | -1.875389 | 0.689938 |
| 179 | 0.183550 | 1.683339 |
| 180 | 0.220839 | 1.396213 |
| 181 | 0.660952 | 1.921363 |
| 182 | -2.357542 | 1.145418 |
| 183 | 0.521454 | 0.304456 |
| 184 | -0.321098 | -1.072025 |
| 185 | -0.265391 | 1.166742 |
| 186 | 1.182235 | 2.652254 |
| 187 | 0.920143 | 1.772478 |
| 188 | 0.620841 | 1.806727 |
| 189 | -0.892951 | 0.177710 |
| 190 | -0.463518 | 2.034266 |
| 191 | -0.031959 | 0.967620 |
| 192 | -0.412957 | 0.324511 |
| 193 | -0.021698 | 0.949692 |
| 194 | 1.897446 | 2.806375 |
| 195 | -0.346429 | 0.899780 |
| 196 | -0.320803 | -0.144683 |
| 197 | -0.332870 | 0.751261 |
| 198 | -0.579072 | 0.318083 |
| 199 | -0.889261 | 0.091241 |
200 rows × 2 columns
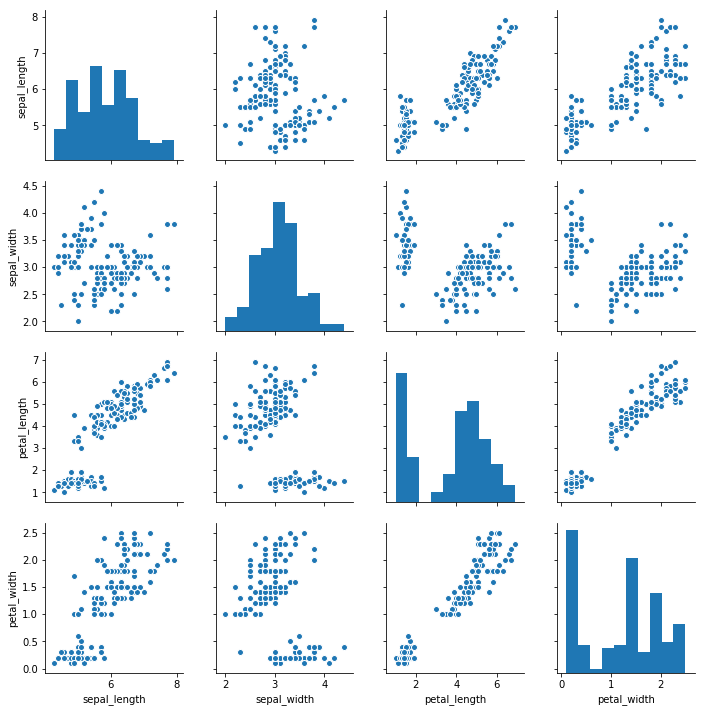
观察两个变量之间的分布关系最好用散点图
1 | sns.jointplot(x="x",y="y",data=df) |
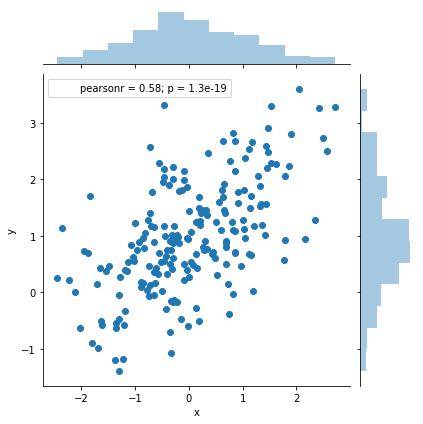
1 | x,y = np.random.multivariate_normal(mean,cov,1000).T |
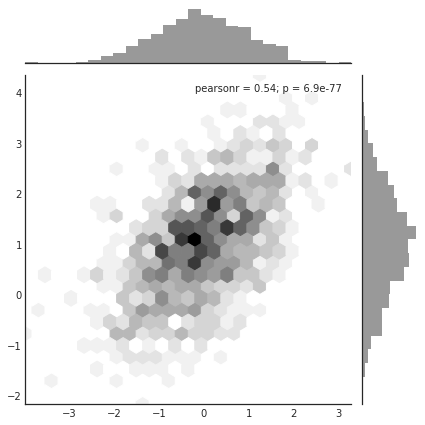
1 | iris = sns.load_dataset("iris") |